
⚫ Hash란 ?
다양한 길이를 가진 데이터[Key]를 고정된 길이를 가진 데이터[Value]로 mapping(하나의 값을 다른 값으로 대응시키는 것) 한 값.
-출처 : hash.kr (해시넷)
- 특정한 배열의 위치(index)나 위치를 입력하고자 하는 데이터의 값을 이용해 저장하거나 찾을 수 있다.
- 탐색이나 삽입에 비해 즉시 저장하거나 찾고자 하는 위치를 참조할 수 있으므로 속도가 빠르다. 시간복잡도(O(1))
- 단방향 암호화 기법이다. : 암호화만 가능
-> 양방향 : 암호화, 복호화 둘 다 가능 ( 복호화 : 암호화된 데이터를 다시 원래의 데이터로 되돌리는 것 )
- 특정 입력값에 대해 항상 같은 해시 값을 리턴한다.
- 해시 알고리즘마다 hash 길이가 다르기에, 입력이 다른 값이지만 해시 값이 같을 수도 있다.
-> 길이제한이 없다면 무한정 찍어낼 수 있지만, 해시값은 고정된 길이의 값이기에 한계가 있을 수 있다.
-> 중복이 적을수록 좋은 해시 함수라고 할 수 있다.
-> 중복 발생시 충돌을 해결하는 코드도 필요하다.
🟠 Hash Function, Hash Table
- Hash function 은 key를 고정된 길이의 data로 매핑하는 함수를 이야기한다.

- 위 그림에서 key를 hash function을 통하면 00,01,02 ,... 와 같은 고정된 길이의 hash들로 표현이 되는 걸 볼 수 있는데, 각 해당 index에 전화번호를 저장할 때 buckets 속에 저장되는 전화번호는 hash function과 아무련 연관이 없다. 각 hash 값에 맞는 위치에 전화번호를 그냥 저장만 할 뿐이다.
-> Hash Table : key를 hash function에 넣어 얻은 hash들을 index로 value 데이터와 mapping 하는 배열 및 테이블의 구조
🟡 동작 원리
🧨 1. Hash 값을 만드는 과정
-> hash function(key){ return Hash; } : O(1)
hash table의 index화를 위해 hash function을 사용하는 것을 hashing 이라고 한다. hash를 구하는 방식은 내부에서 정한 대로 연산만 하고 return 하면 되기 대문에 시간복잡도가 O(1)이 되는 것이다.
🧨 2. Hash table에서 해당 index로 이동하는 과정
-> Arr[hash] : O(1)
hash값을 index로 사용하여 참조하기만 하면 되므로 시간복잡도가 O(1)이다.
🟢 충돌 해결
💣 1. Chaining

동일한 index에 대해 data에 key와 value 말고도 다음 데이터의 주소를 같이 저장하는 것
-> linked data struct
🌟 장점
- 제한된 bucket을 효율적으로 사용가능 (테이블 확장이 필요없음)
- 공간을 미리 할당할 필요가 없기에 메모리 사용량이 줄어든다. (메모리를 추가로 사용하긴 한다)
- 다음 주소를 가리기는 link를 통해 추가할 수 있는 데이터의 제약이 줄어든다.
🌃 단점
- 최악의 경우 모든 노드가 한 bucket에 삽입될 수 있다.
- 다양한 key에 대한 동일한 hash가 많고, 하나의 bucket에 여러 항목이 들어갈수록 효율성이 떨어진다.
요약:
평균적으로 hash가 골고루 분포하면 O(1 + n ) ~ 모든 키가 하나의 slot에 할당되면 O(n)
💣 2. Open Addressing

충돌이 발생하면 다른 테이블 공간을 탐사해 빈 공간을 찾고 거기에 데이터를 저장하는 방식
충돌이 발생한 위치부터 순차적으로 하나씩 탐색해나가는 방식이다. 빈 메모리를 찾을 때 까지
2-1. Linear Probing : 현재 bucket의 index 부터 고정폭만큼 차례대로 이동하면서 탐색

문제점 : 빈 곳을 채우고, 그 다음 빈 곳을 채우다보니 data가 한쪽에 몰리는 현상이 발생한다. -> clustering
2-2. Quadratic Probing : 고정폭을 제곱으로 저장하는 방식. (2^2, 3^2 칸씩 옮기는 방식)
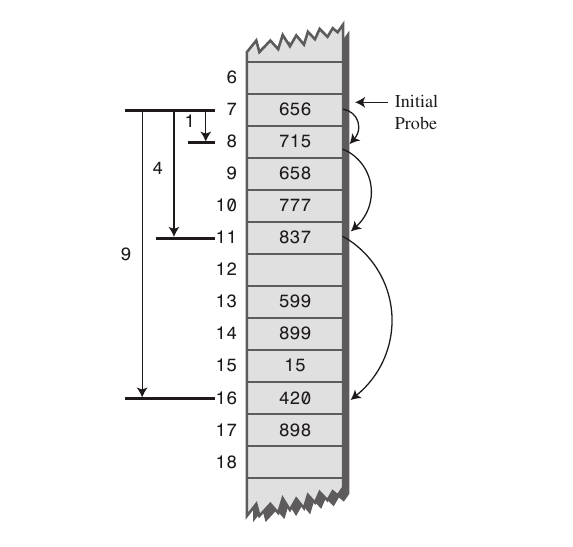
문제점 : 첫 hash 위치가 같으면 ^으로 멀리 나아가면서도 중복이 생긴다. (2차 클러스터링)
-> 처음은 2^2 인데 다음 타자는 2^2가 선점되었으므로 3^2 이런방식.
2-3. Double Probing : 해시된 값을 한 번더 해싱하여 새로운 주소를 할당해버리는 방식.

문제점 : Quadratic 과 마찬가지로 2차 클러스터링 발생가능. 두 key의 처음 hash값이 동일하다면 빈 slot을 찾는 과정 알고리즘이 동일함으로 같은 slot을 탐색하게 된다. 따라서 Double Probing이 아닌 Double Hasing을 통해 2차 클러스터링을 방지해야한다.
🟣 Double Hasing == Coalesced Hasing
Chaining과 open-addressing 을 혼합한 방식으로, 탐색키를 참조하여 더해지는 값으로 결정한다.
hash값 + 그 hash를 나오게한 처음 key 를 hash화하여 나온 다른 index에 data를 저장.
🔵 ReSizing
해시 테이블 내에서 데이터를 저장할 수 있는 버킷을 늘려주는 것. 자료구조의 크기가 늘어나는 게 아니라 임의로 버킷수를 할당하면서 늘려주는것. 코드로 봐야할 것 같다.
Best Solution : 애초에 충돌을 만들지 않는 좋은 성능의 Hash Fcuntion + Resizing